Artificial intelligence holds an enormous promise, but to be effective, it must learn from massive sets of data—and the more diverse the better. By learning patterns, AI tools can uncover insights and help decision-making not just in technology, but also pharmaceuticals, medicine, manufacturing, and more. However, data can’t always be shared—whether it’s personally identifiable, holds proprietary information, or to do so would be a security concern—until now.
“It’s going to be a new age.” Says Dr. Eng Lim Goh, senior vice president and CTO of artificial intelligence at Hewlett Packard Enterprise. “The world will shift from one where you have centralized data, what we’ve been used to for decades, to one where you have to be comfortable with data being everywhere.”
Data everywhere means the edge, where each device, server, and cloud instance collect massive amounts of data. One estimate has the number of connected devices at the edge increasing to 50 billion by 2022. The conundrum: how to keep collected data secure but also be able to share learnings from the data, which, in turn, helps teach AI to be smarter. Enter swarm learning.
Swarm learning, or swarm intelligence, is how swarms of bees or birds move in response to their environment. When applied to data Goh explains, there is “more peer-to-peer communications, more peer-to-peer collaboration, more peer-to-peer learning.” And Goh continues, “That’s the reason why swarm learning will become more and more important as …as the center of gravity shifts” from centralized to decentralized data.
Consider this example, says Goh. “A hospital trains their machine learning models on chest X-rays and sees a lot of tuberculosis cases, but very little of lung collapsed cases. So therefore, this neural network model, when trained, will be very sensitive to what’s detecting tuberculosis and less sensitive towards detecting lung collapse.” Goh continues, “However, we get the converse of it in another hospital. So what you really want is to have these two hospitals combine their data so that the resulting neural network model can predict both situations better. But since you can’t share that data, swarm learning comes in to help reduce that bias of both the hospitals.”
And this means, “each hospital is able to predict outcomes, with accuracy and with reduced bias, as though you have collected all the patient data globally in one place and learned from it,” says Goh.
And it’s not just hospital and patient data that must be kept secure. Goh emphasizes “What swarm learning does is to try to avoid that sharing of data, or totally prevent the sharing of data, to [a model] where you only share the insights, you share the learnings. And that’s why it is fundamentally more secure.”
Show notes and links:
Full transcript:
Laurel Ruma: From MIT Technology Review, I’m Laurel Ruma. And this is Business Lab, the show that helps business leaders make sense of new technologies coming out of the lab and into the marketplace. Our topic today is decentralized data. Whether it’s from devices, sensors, cars, the edge, if you will, the amount of data collected is growing. It can be personal and it must be protected. But is there a way to share insights and algorithms securely to help other companies and organizations and even vaccine researchers?
Two words for you: swarm learning.
My guest is Dr. Eng Lim Goh, who’s the senior vice president and CTO of artificial intelligence at Hewlett Packard Enterprise. Prior to this role, he was CTO for a majority of his 27 years at Silicon Graphics, now an HPE company. Dr. Goh was awarded NASA’s Exceptional Technology Achievement Medal for his work on AI in the International Space Station. He has also worked on numerous artificial intelligence research projects from F1 racing, to poker bots, to brain simulations. Dr. Goh holds a number of patents and had a publication land on the cover of Nature. This episode of Business Lab is produced in association with Hewlett Packard Enterprise. Welcome Dr. Goh.
Dr. Eng Lim Goh: Thank you for having me.
Laurel: So, we’ve started a new decade with a global pandemic. The urgency of finding a vaccine has allowed for greater information sharing between researchers, governments and companies. For example, the World Health Organization made the Pfizer vaccine’s mRNA sequence public to help researchers. How are you thinking about opportunities like this coming out of the pandemic?
Eng Lim: In science and medicine and others, sharing of findings is an important part of advancing science. So the traditional way is publications. The thing is, in a year, year and a half, of covid-19, there has been a surge of publications related to covid-19. One aggregator had, for example, the order of 300,000 of such documents related to covid-19 out there. It gets difficult, because of the amount of data, to be able to get what you need.
So a number of companies, organizations, started to build these natural language processing tools, AI tools, to allow you to ask very specific questions, not just search for keywords, but very specific questions so that you can get the answer that you need from this corpus of documents out there. A scientist could ask, or a researcher could ask, what is the binding energy of the SARS-CoV-2 spike protein to our ACE-2 receptor? And can be even more specific and saying, I want it in units of kcal per mol. And the system would go through. The NLP system would go through this corpus of documents and come up with an answer specific to that question, and even point to the area of the documents, where the answer could be. So this is one area. To help with sharing, you could build AI tools to help go through this enormous amount of data that has been generated.
The other area of sharing is sharing of a clinical trial data, as you have mentioned. Early last year, before any of the SARS-CoV-2 vaccine clinical trials had started, we were given the yellow fever vaccine clinical trial data. And even more specifically, the gene expression data from the volunteers of the clinical trial. And one of the goals is, can you analyze the tens of thousands of these genes being expressed by the volunteers and help predict, for each volunteer, whether he or she would get side-effects from this vaccine, and whether he or she will give good antibody response to this vaccine? So building predictive tools by sharing this clinical trial data, albeit anonymized and in a restricted way.
Laurel: When we talk about natural language processing, I think the two takeaways that we’ve taken from that very specific example are, you can build better AI tools to help the researchers. And then also, it helps build predictive tools and models.
Eng Lim: Yes, absolutely.
Laurel: So, as a specific example of what you’ve been working on for the past year, Nature Magazine recently published an article about how a collaborative approach to data insights can help these stakeholders, especially during a pandemic. What did you find out during that work?
Eng Lim: Yes. This is related, again, to the sharing point you brought about, how to share learning so that the community can advance faster. The Nature publication you mentioned, the title of it is “Swarm Learning [for Decentralized and Confidential Clinical Machine Learning]”. Let’s use the hospital example. There is this hospital, and it sees its patients, the hospital’s patients, of a certain demographic. And if it wants to build a machine learning model to predict based on patient data, say for example a patient’s CT scan data, to try and predict certain outcomes. The issue with learning in isolation like this is, you start to evolve models through this learning of your patient data biased to what’s the demographics you are seeing. Or in other ways, biased towards the type of medical devices you have.
The solution to this is to collect data from different hospitals, maybe from different regions or even different countries. And then combine all these hospitals’ data and then train the machine learning model on the combined data. The issue with this is that privacy of patient data prevents you from sharing that data. Swarm learning comes in to try and solve this, in two ways. One, instead of collecting data from these different hospitals, we allow each hospital to train their machine learning model on their own private patient data. And then occasionally, a blockchain comes in. That’s the second way. A blockchain comes in and collects all the learnings. I emphasize. The learnings, and not the patient data. Collect only the learnings and combine it with the learnings from other hospitals in other regions and other countries, average them and then send back down to all the hospitals, the updated globally combined averaged learnings.
And by learnings I mean the parameters, for example, of the neural network weights. The parameters which are the neural network weights in the machine learning model. So in this case, no patient data ever leaves an individual hospital. What leaves the hospital is only the learnings, the parameters or the neural network weights. And so, when you sent up your locally learned parameters, and what you get back from the blockchain is the global averaged parameters. And then you update your model with the global average, and then you carry on learning locally again. After a few cycles of these sharing of learnings, we’ve tested it, each hospital is able to predict, with accuracy and with reduced bias, as though you have collected all the patient data globally in one place, and learned from it.
Laurel: And the reason that blockchain is used is because it is actually a secure connection between various, in this case, machines, correct?
Eng Lim: There are two reasons, yes, why we use blockchain. The first reason is the security of it. And number two, we can keep that information private because, in a private blockchain, only participants, main participants or certified participants, are allowed in this blockchain. Now, even if the blockchain is compromised, what is only seen are the weights or the parameters of the learnings, not the private patient data, because the private patient data is not in the blockchain.
And the second reason for using a blockchain, it is as opposed to having a central custodian that does the collection of the parameters, of the learnings. Because once you appoint a custodian, an entity, that collects all these learnings, if one of the hospitals becomes that custodian, then you have a situation where that appointed custodian has more information than the rest, or has more capability than the rest. Not so much more information, but more capability than the rest. So in order to have a more equitable sharing, we use a blockchain. And in the blockchain system, what it does is that randomly appoints one of the participants as the collector, as the leader, to collect the parameters, average it and send it back down. And in the next cycle, randomly, another participant is appointed.
Laurel: So, there’s two interesting points here. One is, this project succeeds because you are not using only your own data. You are allowed to opt into this relationship to use the learnings from other researchers’ data as well. So that reduces bias. So that’s one kind of large problem solved. But then also this other interesting issue of equity and how even algorithms can perhaps be less equitable from time to time. But when you have an intentionally random algorithm in the blockchain assigning leadership for the collection of the learnings from each entity, that helps strip out any kind of possible bias as well, correct?
Eng Lim: Yes, yes, yes. Brilliant summary, Laurel. So there’s the first bias, which is, if you are learning in isolation, the hospital is learning, a neural network model, or a machine learning model, more generally, of a hospital is learning in isolation only on their own private patient data, they will be naturally biased towards the demographics they are seeing. For example, we have an example where a hospital trains their machine learning models on chest x-rays and sees a lot of tuberculosis cases. But very little of lung collapsed cases. So therefore, this neural network model, when trained, will be very sensitive to what’s detecting tuberculosis and less sensitive towards detecting lung collapse, for example. However, we get the converse of it in another hospital. So what you really want is to have these two hospitals combine their data so that the resulting neural network model can predict both situations better. But since you can’t share that data, swarm learning comes in to help reduce that bias of both the hospitals.
Laurel: All right. So we have an enormous amount of data. And it keeps growing exponentially as the edge, which is really any data generating device, system or sensor, expands. So how is decentralized data changing the way companies need to think about data?
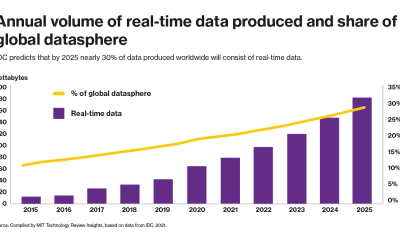
Eng Lim: Oh, that’s a profound question. There is one estimate that says that by next year, by the year 2022, there will be 50 billion connected devices at the edge. And this is growing fast. And we’re coming to a point that we have an average of about 10 connected devices potentially collecting data, per person, in this world. Given that situation, the center of gravity will shift from the data center being the main location generating data to one where the center of gravity will be at the edge in terms of where data is generated. And this will change dynamics tremendously for enterprises. You will therefore see the need for these devices that are out there where this enormous amount of data generated at the edge with so much of these devices out there that you’ll reach a point where you cannot afford to backhaul or bring back all that data to the cloud or data center anymore.
Even with 5G, 6G and so on. The growth of data will outstrip that, will far exceed that of the growth in bandwidth of these new telecommunication capabilities. As such, you’ll reach a point where you have no choice but to push the intelligence to the edge so that you can decide what data to move back to the cloud or data center. So it’s going to be a new age. The world will shift from one where you have centralized data, what we’ve been used to for decades, to one where you have to be comfortable with data being everywhere. And when that’s the case, you need to do more peer-to-peer communications, more peer-to-peer collaboration, more peer-to-peer learning.
And that’s the reason why swarm learning will become more and more important as this progresses, as the center of gravity shifts out there from one where data is centralized, to one where data is everywhere.
Laurel: Could you talk a little bit more about how swarm intelligence is secure by design? In other words, it allows companies to share insights from data learnings with outside enterprises, or even within groups in a company, but then they don’t actually share the actual data?
Eng Lim: Yes. Fundamentally, when we want to learn from each other, one way is, we share the data so that each of us can learn from each other. What swarm learning does is to try to avoid that sharing of data, or totally prevent the sharing of data, to [a model] where you only share the insights, you share the learnings. And that’s why it is fundamentally more secure, using this approach, where data stays private in the location and never leaves that private entity. What leaves that private entity are only the learnings. And in this case, the neural network weights or the parameters of those learnings.
Now, there are people who are researching the ability to deduce the data from the learnings, it is still in research phase, but we are prepared if it ever works. And that is, in the blockchain, we do homomorphic encryption of the weights, of the parameters, of the learnings. By homomorphic, we mean when the appointed leader collects all these weights and then averages them, you can average them in the encrypted form so that if someone intercepts the blockchain, they see encrypted learnings. They don’t see the learnings themselves. But we’ve not implemented that yet, because we don’t see it necessary yet until such time we see that being able to reverse engineer the data from the learnings becomes feasible.
Laurel: And so, when we think about increasing rules and legislation surrounding data, like GDPR and California’s CCPA, there needs to be some sort of solution to privacy concerns. Do you see swarm learning as one of those possible options as companies grow the amount of data they have?
Eng Lim: Yes, as an option. First, if there is a need for edge devices to learn from each other, swarm learning is there, is useful for it. And number two, as you are learning, you do not want the data from each entity or participant in swarm learning to leave that entity. It should only stay where it is. And what leaves is only the parameters and the learnings. You see that not just in a hospital scenario, but you see that in finance. Credit card companies, for example, of course, wouldn’t want to share their customer data with another competitor credit card company. But they know that the learnings of the machine learning models locally is not as sensitive to fraud data because they are not seeing all the different kinds of fraud. Perhaps they’re seeing one kind of fraud, but a different credit card company might be seeing another kind of fraud.
Swarm learning could be used here where each credit card company keeps their customer data private, no sharing of that. But a blockchain comes in and shares the learnings, the fraud data learning, and collects all those learnings, averaged it and giving it back out to all the participating credit card companies. So this is one example. Banks could do the same. Industrial robots could do the same too.
We have an automotive customer that has tens of thousands of industrial robots, but in different countries. Industrial robots today follow instructions. But in the next generation robots, with AI, they will also learn locally, say for example, to avoid certain mistakes and not repeat them. What you can do, using swarm learning is, if these robots are in different countries where you cannot share data, sensor data from the local environment across country borders, but you’re allowed to share the learnings of avoiding these mistakes, swarm learning can therefore be applied. So you now imagine a swarm of industrial robots, across different countries, sharing learnings so that they don’t repeat the same mistakes.
So yes. In enterprise, you can see different applications of swarm learning. Finance, engineering, and of course, in healthcare, as we’ve discussed.
Laurel: How do you think companies need to start thinking differently about their actual data architecture to encourage the ability to share these insights, but not actually share the data?
Eng Lim: First and foremost, we need to be comfortable with the fact that devices that are collecting data will proliferate. And they will be at the edge where the data first lands. What’s the edge? The edge is where you have a device, and where the data first lands electronically. And if you imagine 50 billion of them next year, for example, and growing, in one estimate, we need to be comfortable with the fact that data will be everywhere. And to design your organization, design the way you use data, design the way you access data with that concept in mind, i.e., moving from one which we are used to, that is data being centralized most of the time, to one where data is everywhere. So the way you access data needs to be different now. You cannot now think of first aggregating all the data, pulling all the data, backhauling all the data from the edge to a centralized location, then work with it. We may need to switch to a scenario where we are operating on the data, learning from the data while the data are still out there.
Laurel: So, we talked a bit healthcare and manufacturing. How do you also envision the big ideas of smart cities and autonomous vehicles fitting in with the ideas of swarm intelligence?
Eng Lim: Yes, yes, yes. These are two big, big items. And very similar also, you think of a smart city, it is full of sensors, full of connected devices. You think of autonomous cars, one estimate puts it at something like 300 sensing devices in a car, all collecting data. A similar way of thinking of it, data is going to be everywhere, and collected in real time at these edge devices. For smart cities, it could be street lights. We work with one city with 200,000 street lights. And they want to make every one of these street lights smart. By smart, I mean ability to recommend decisions or even make decisions. You get to a point where, as I’ve said before, you cannot backhaul all the data all the time to the data center and make decisions after you’ve done the aggregation. A lot of times you have to make decisions where the data is collected. And therefore, things have to be smart at the edge, number one.
And if we take that step further beyond acting on instructions or acting on neural network models that have been pre-trained and then sent to the edge, you take one step beyond that, and that is, you want the edge devices to also learn on their own from the data they have collected. However, knowing that the data collected is biased to what they are only seeing, swarm learning will be needed in a peer-to-peer way for these devices to learn from each other.
So, this interconnectedness, the peer-to-peer interconnectedness of these edge devices, requires us to rethink or change the way we think about computing. Just take for example two autonomous cars. We call them connected cars to start with. Two connected cars, one in front of the other by 300 yards or 300 meters. The one in front, with lots of sensors in it, say for example in the shock absorbers, senses a pothole. And it actually can offer that sensed data that there is a pothole coming up to the cars behind. And if the cars behind switch on to automatically accept these, that pothole shows up on the car behind’s dashboard. And the car behind just pays maybe 0.10 cent for that information to the car in front.
So, you get a situation where you get these peer-to-peer sharing, in real time, without needing to send all that data first back to some central location and then send back down then the new information to the car behind. So, you want it to be peer-to-peer. So more and more, I’m not saying this is implemented yet, but this gives you an idea of how thinking can change going forward. A lot more peer-to-peer sharing, and a lot more peer-to-peer learning.
Laurel: When you think about how long we’ve worked in the technology industry to think that peer-to-peer as a phrase has come back around, where it used to mean people or even computers sharing various bits of information over the internet. Now it is devices and sensors sharing bits of information with each other. Sort of a different definition of peer-to-peer.
Eng Lim: Yeah. Thinking is changing. And peer, the word peer, peer-to-peer, meaning it has the connotation of a more equitable sharing in there. That’s the reason why a blockchain is needed in some of these cases so that there is no central custodian to average the learnings, to combine the learnings. So you want a true peer-to-peer environment. And that’s what swarm learning is built for. And now the reason for that, it’s not because we feel peer-to-peer is the next big thing and therefore we should do it. It is because of data and the proliferation of these devices that are collecting data.
Imagine tens of billions of these out there, and every one of these devices getting to be smarter and consuming less energy to be that smart and moving from one where they follow instructions or infer from the pre-trained neural network model given to them, to one where they can even advance towards learning on their own. But knowing that these devices are so many of them out there, therefore each of them are only seeing a small portion. Small is still big if you combine that all of them, 50 billion of them. But each of them is only seeing a small portion of data. And therefore, if they just learn in isolation, they’ll be highly biased towards what they’re seeing. As such, there must be some way where they can share their learnings without having to share their private data. And therefore, swarm learning. As opposed to backhauling all that data from the 50 billion edge devices back to these cloud locations, the data center locations, so they can do the combined learning.
Laurel: Which would cost certainly more than a fraction of a cent.
Eng Lim: Oh yeah. There is a saying, bandwidth, you pay for. Latency, you sweat for. So it’s cost. Bandwidth is cost.
Laurel: So as an expert in artificial intelligence, while we have you here, what are you most excited about in the coming years? What are you seeing that you’re thinking, that is going to be something big in the next five, 10 years?
Eng Lim:
Thank you, Laurel. I don’t see myself as an expert in AI, but a person that is being tasked and excited about working with customers on AI use cases and learning from them. The diversity of these different AI use cases and learning from them–some leading teams directly working on the projects and overseeing some of the projects. But in terms of the excitement, actually may seem mundane. And that is, the exciting part is that I see AI. The ability for smart systems to learn and adapt, and in many cases, provide decision support to humans. And in other more limited cases, make decisions in support of humans. The proliferation of AI is in everything we do, many things we do—certain things maybe we should limit—but in many things we do.
I mean, let’s just use the most basic of examples. How this progression could be. Let’s take a light switch. In the early days, even until today, the most basic light switch is one where it is manual. A human goes ahead, throws the switch on, and the light comes on. And throws the switch off, and the light goes off. Then we move on to the next level. If you want an analogy, more next level, where we automate that switch. We put a set of instructions on that switch with a light meter, and set the instructions to say, if the lighting in this room drops to 25% of its peak, switch on. So basically, we gave an instruction with a sensor to go with it, to the switch. And then the switch is now automatic. And then when the lighting in the room drops to 25% of its peak, of the peak illumination, it switches on the lights. So now the switch is automated.
Now we can even take a step further in that automation, by making the switch smart, in that it can have more sensors. And then through the combinations of sensors, make decisions as to whether the switch the light on. And the control all these sensors, we built a neural network model that has been pre-trained separately, and then downloaded onto the switch. This is where we are at today. The switch is now smart. Smart city, smart street lights, autonomous cars, and so on.
Now, is there another level beyond that? There is. And that is when the switch not just follows instructions or not just have a trained neural network model to decide in a way to combine all the different sensor data, to decide when to switch the light on in a more precise way. It advances further to one where it learns. That’s the key word. It learns from mistakes. What would be the example? The example would be, based on the neural network model it has, that was pre-trained previously, downloaded onto the switch, with all the settings. It turns the light on. But when the human comes in, the human says I don’t need the light on here this time around, the human switches the light off. Then the switch realizes that it actually made a decision that the human didn’t like. So after a few of these, it starts to adapt itself, learn from these. Adapt itself so that you can switch a light on to the changing human preferences. That’s the next step where you want edge devices that are collecting data at the edge to learn from those.
Then of course, if you take that even further, all the switches in this office or in a residential unit, learn from each other. That will be swarm learning. So if you then extend the switch to toasters, to fridges, to cars, to industrial robots and so on, you will see that doing this, we will clearly reduce energy consumption, reduce waste, and improve productivity. But the key must be, for human good.
Laurel: And what a wonderful way to end our conversation. Thank you so much for joining us on the Business Lab.
Eng Lim: Thank you Laurel. Much appreciated.
Laurel: That was Dr. Eng Lim Goh, senior vice president and CTO of artificial intelligence at Hewlett Packard Enterprise, who I spoke with from Cambridge, Massachusetts, the home of MIT and MIT Technology Review, overlooking the Charles River. That’s it for this episode of Business Lab, I’m your host, Laurel Ruma. I’m the director of Insights, the custom publishing division of MIT Technology Review. We were founded in 1899 at the Massachusetts Institute of Technology. And you can find us in print, on the web, and at events each year around the world. For more information about us and the show, please check out our website at technologyreview.com. The show is available wherever you get your podcasts. If you enjoyed this episode, we hope you’ll take a moment to rate and review us. Business Lab is a production of MIT Technology Review. This episode was produced by Collective Next. Thanks for listening.
This podcast episode was produced by Insights, the custom content arm of MIT Technology Review. It was not produced by MIT Technology Review’s editorial staff.